Imagine you are asked to copy a sentence onto a fresh sheet of paper. There are two ways of copying: you could transfer every individual letter (t, h, e, _...), or you could leverage your familiarity with English to copy a few words at a time. For example, if you already know how to write "windowpane," you don't need to individually copy each character: you can just write windowpane.
Olsson et al. (2022) previously showed that LLMs copy on a "letter-by-letter" basis, using induction heads to copy one token at a time. But can LLMs also copy the second way, on a semantic level? In this work, we differentiate two types of induction heads: token induction heads, which copy bit-by-bit, and concept induction heads, which copy word meanings instead of individual tokens. Concept induction heads work together with token induction heads to copy meaningful text. We call this synergy the "dual-route model of induction."
Inspiration: How do Humans Read?
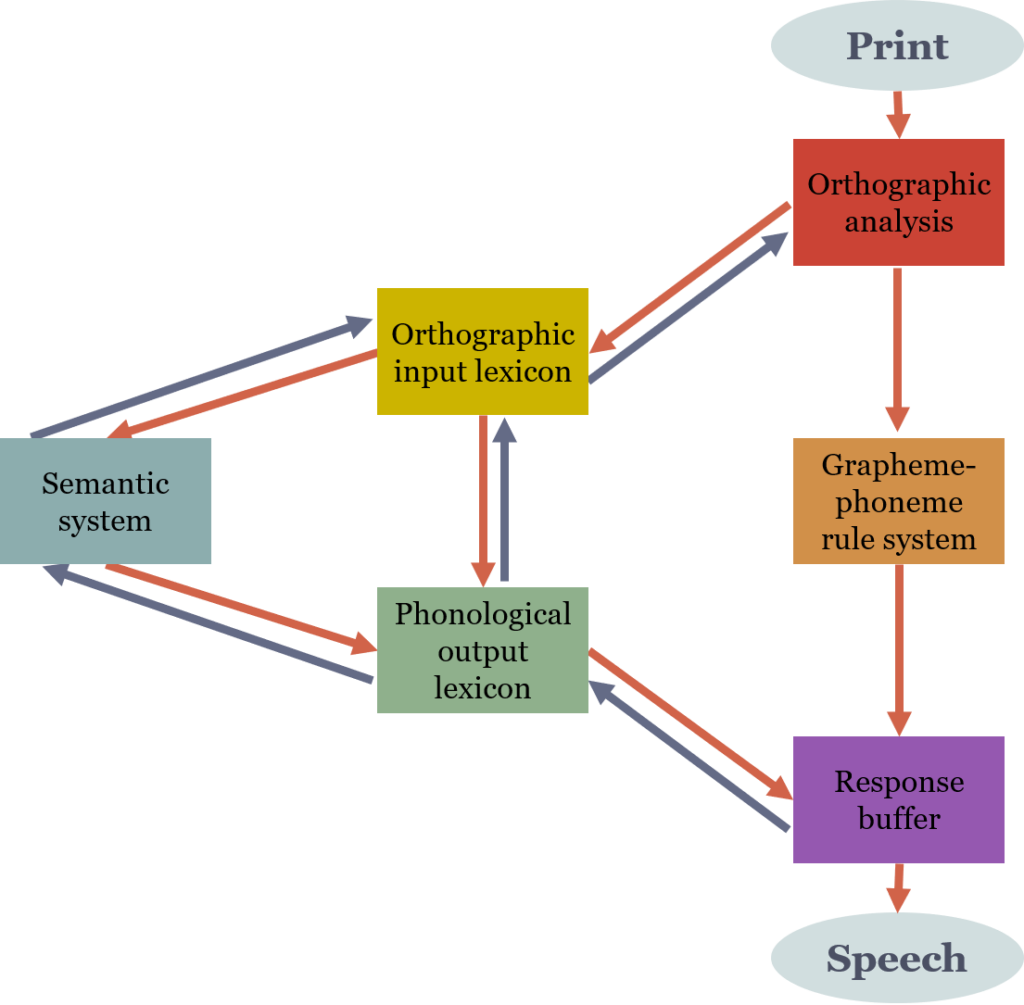
Psychologists have developed a dual-route model of reading, which describes two ways that humans can read text (see this textbook section and Wikipedia). If readers are looking at a word they already know, they can read it via a lexical pathway that processes whole words at a time, as if they are looking up those words in a dictionary. On the other hand, if readers come across a word they do not know, they must use the sub-lexical route, which decodes individual graphemes into phonemes based on the rules of that language.
Image depicting the dual-route model of reading aloud. Given printed text, a reader can convert from graphemes into phonemes to create speech, or they can map printed words to their semantic meanings and retrieve the pronunciations of those word meanings. (Credit: Ramoo, D. (2021). Psychology of Language. United States: BCcampus, BC Open Textbook Project.)
The existence of a condition called deep dyslexia provides support for this model. After an accident or stroke, people with deep dyslexia can still read and understand word meanings, but often make semantic errors when reading words aloud. For example, someone with deep dyslexia might read the word CANARY as "parrot", or BUCKET as "pail." The first documented case of deep dyslexia came from Marshall and Newcombe (1966), and was later complemented by the discovery of the opposite condition, surface dyslexia, an inability to read without first "sounding out" words (Marshall and Newcombe, 1973).
Our Work: Dual-Route Induction
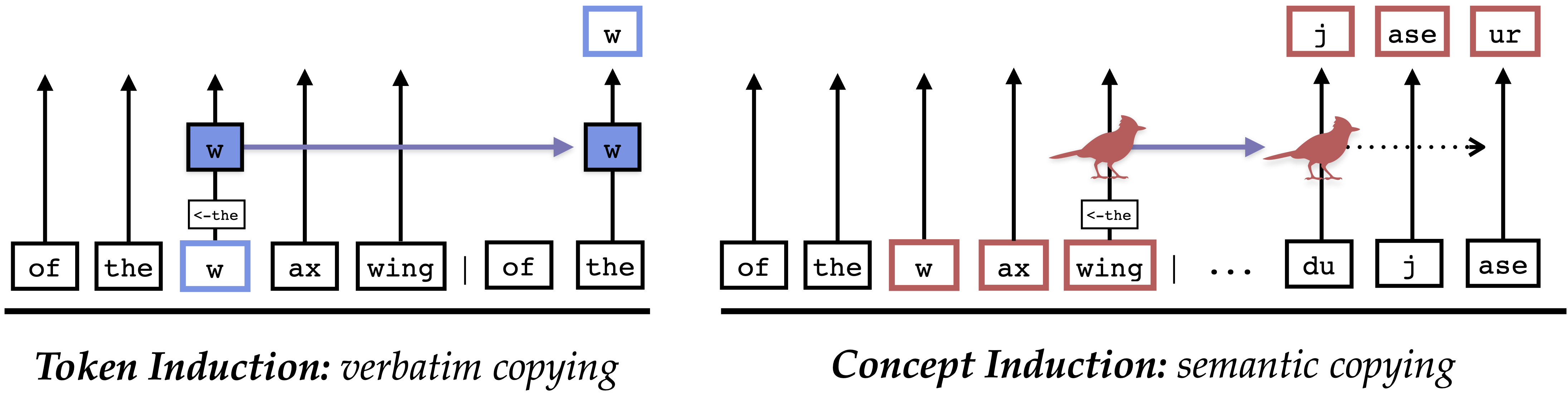
Inspired by this understanding of human reading, we posit a dual-route model of induction. LLMs can either copy text using token-level induction heads (Elhage et al., 2021; Olsson et al., 2022), or using concept-level induction heads, which copy meaningful representations of entire words. In this paper, we identify concept induction heads in four open-source models, and show that they handle word meanings, which also makes them useful for tasks like translating a word between two languages.
Our dual-route model of induction. LLMs develop token induction heads, which are used for verbatim copying, and concept induction heads, important for translation and "fuzzy" copying tasks. These two routes work in parallel to copy meaningful text.
How To Find These Heads?
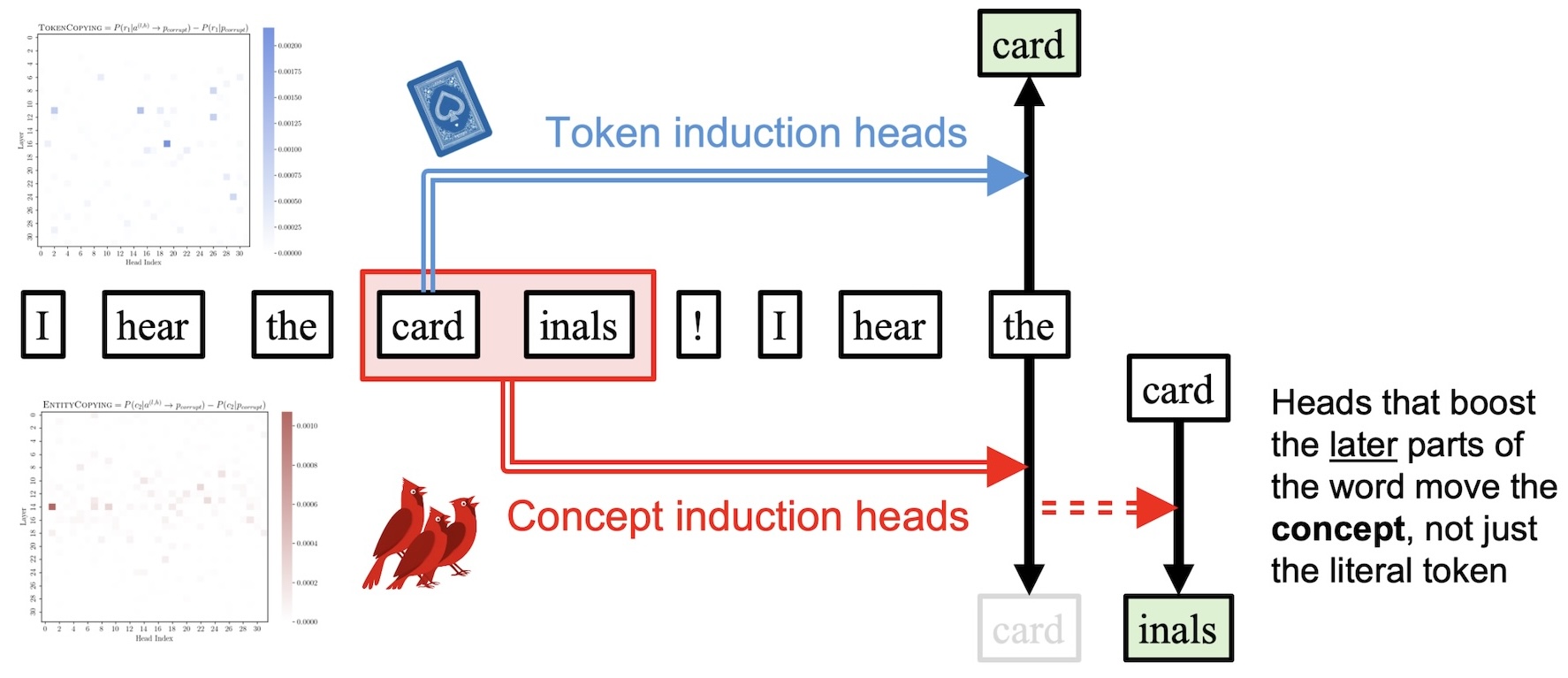
Many words (like "cardinals", shown below) are chopped into nonsensical bits by tokenizers, meaning that models must learn that card and inals actually map to one specific meaning. This process is known as "detokenization" (Elhage et al., 2022, Gurnee et al., 2023). But if the model wants to copy the word "cardinals," it has to convert that latent representation back into the tokens card and inals.
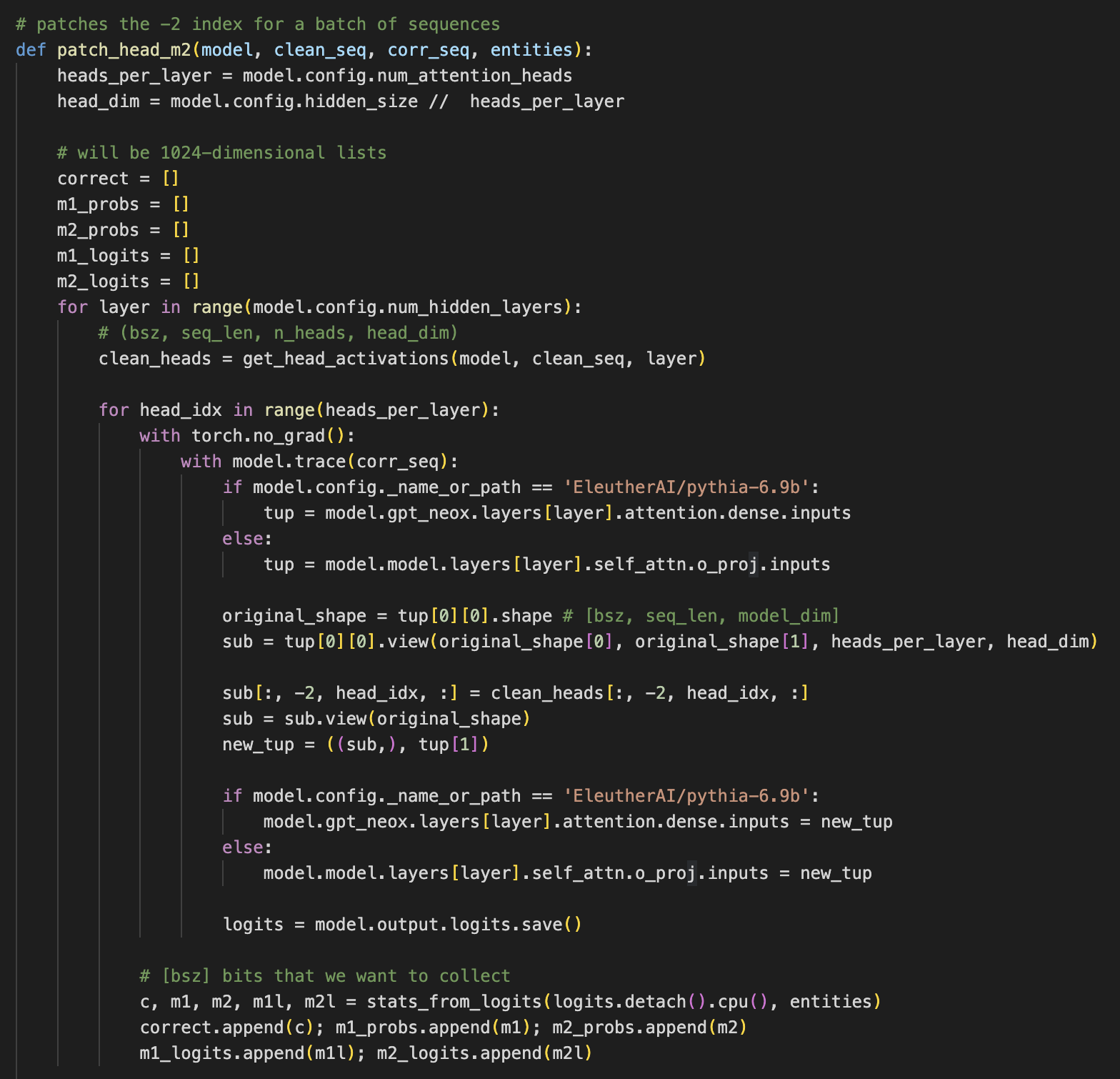
We hypothesize that if an attention head is copying over the meaning of one of these multi-token words, it should have information about all tokens in that word. That means it should increase the probability of future tokens when patched into a new context, not just the next token.
So, if we patch an attention head into a new sequence and it increases the probability of the next copied token, we know it is doing some type of copying. But it if also increases the probability of the token after that, then we hypothesize that it is carrying the entire detokenized word representation.
If an attention head promotes future tokens in a multi-token word, we hypothesize that this head carries the entire word representation.
Ablating Concept and Token Heads
After identifying token and concept induction heads via causal intervention (see Section 2 of our paper), we test these heads on a new in-context task that requires models to copy word meanings. For example, we give an LLM a list of ten words in French (1. neige, 2. pomme, ... 9. froid, 10. mort) and prompt the model to output the translation of the last word in English (... 9. cold, 10. ___). We also set up tasks where the model has to copy exactly from English -> English.
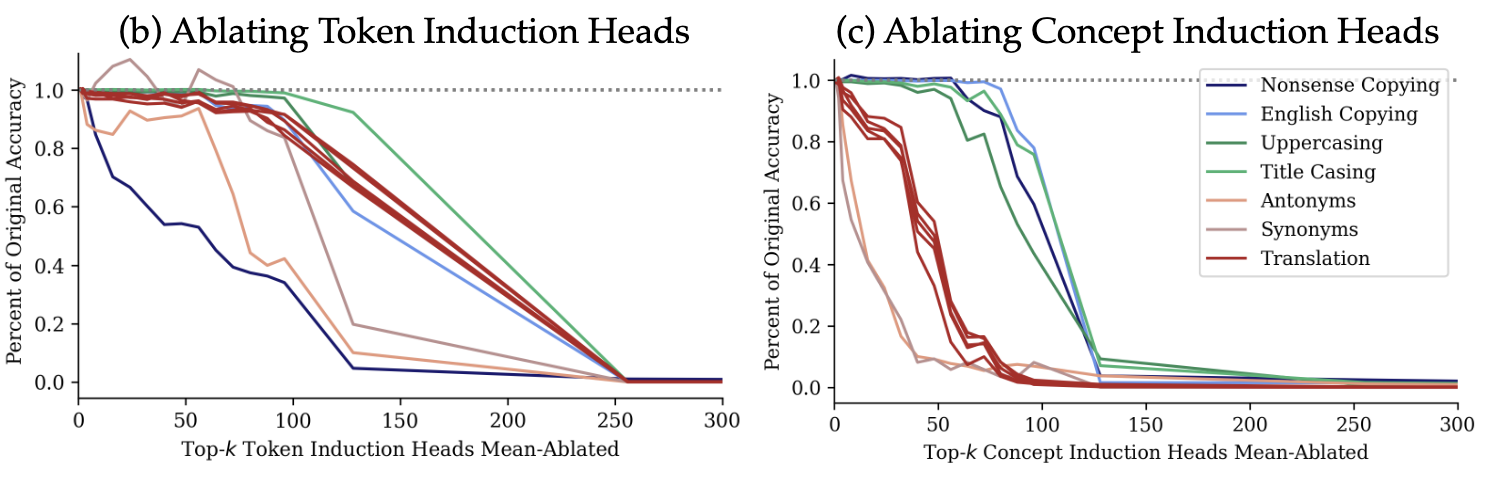
Ablating token induction heads for Llama-2-7b destroys performance for nonsense copying (dark blue), whereas ablating concept induction heads destroys performance for semantic tasks (red).
You can see the difference between these two sets of heads when you compare the red and dark blue lines. When token induction heads are ablated, we see that performance goes down much faster for "nonsense copying" (exSh -> exSh) than for other, meaning-based tasks. This is because models can still use concept induction heads for tasks that require copying word meaning. On the other hand, when concept induction heads are ablated, accuracy for translation, synonyms, and antonyms drops off quickly, while token-based tasks remain intact.
We find that ablating either set of heads has little impact on Llama-2-7b's ability to copy English words, which makes sense: as our intro example demonstrates, you can copy windowpane -> windowpane whether or not you understand the meaning of that word. Because either mechanism can be used to do this task, we think of these two types of heads as working in parallel.
When token induction heads are ablated, we find that LLMs start to paraphrase where they would have otherwise done exact copying. We can think of this as "giving the model deep dyslexia"—it is still able to understand semantics, but is no longer able to access exact token information. Much of this rephrasing seems to be on a phrase level, although we do see specific words being replaced with synonyms (e.g., cases is replaced by times). Section 4.2 and Appendix D.4 show examples of this, and you can also download a notebook to generate paraphrases yourself on GitHub.
(Llama-2-7b) Original Model vs. Top-32 Token Induction Heads Ablated
I have reread, not without pleasure, my comments to his lines, and in many cases have caught myself borrowing a kind of opalescent light from my poet's fiery orb.
I have reread, not without pleasure, my comments to his lines, and in many cases have caught myself borrowing a kind of opalescent light from my poet's fiery orb.
...
I have reread my comments on his lines, and I have caught myself many times borrowing from his fiery orb a kind of opalescent light.
(Llama-3-8b) Original Model vs. Top-32 Token Induction Heads Ablated
foo = []
for i in range(len(bar)):
if i % 2 == 0:
foo.append(bar[i])
foo = [] for i in range(len(bar)):if i % 2 == 0:foo.append(bar[i])
foo = []
for i in range(len(bar)):
if i % 2 == 0:
foo.append(bar[i])
foo = [bar[i] for i in range( len(bar)) if i % 2 == 0]
Concept Lens: What Are These Heads Looking At?
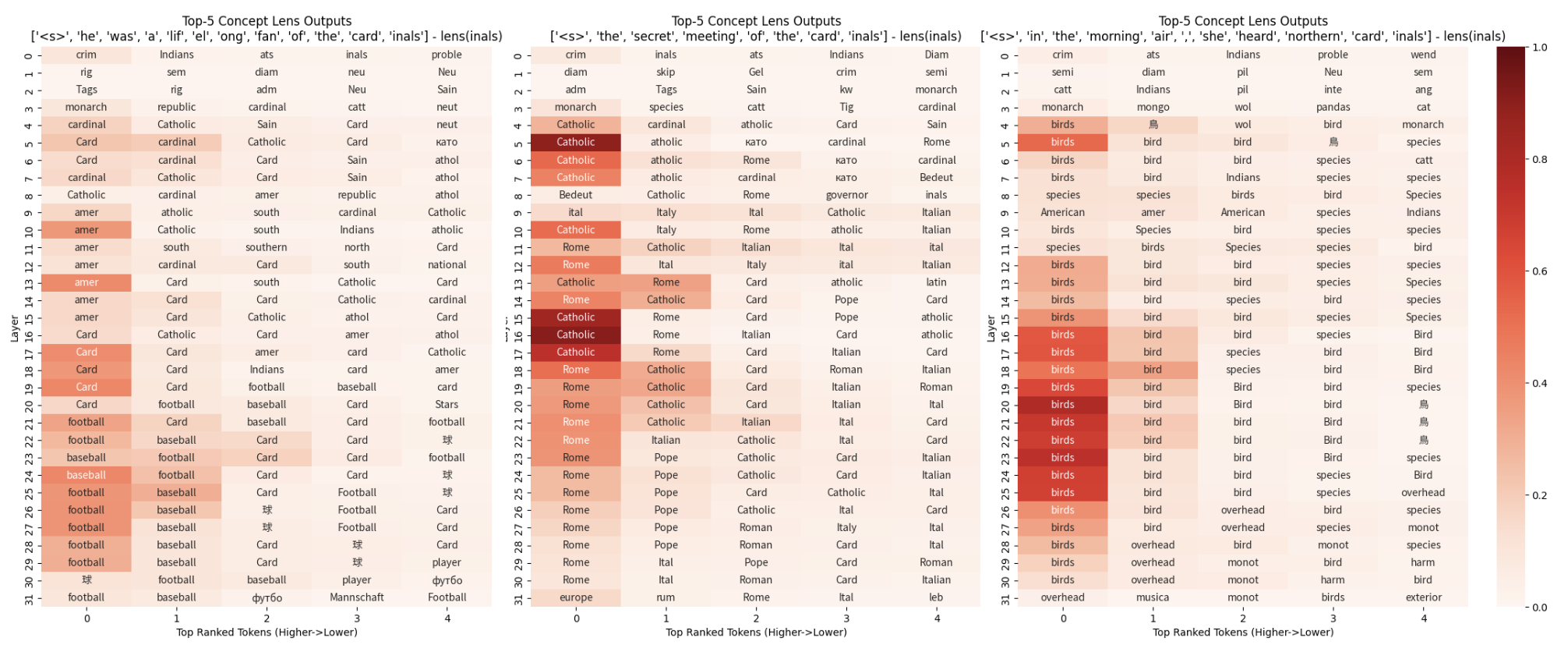
In this paper, we show that concept induction heads carry meaningful word representations. That means we can use the weights of these attention heads to develop a "concept lens" that reveals the semantics of arbitrary hidden states in a model. By combining the output and value projections of the top-k concept induction heads, we can obtain a single matrix that extracts semantic information from any hidden state in our model. For example, if we apply this matrix to a hidden state and project it to token space using logit lens (nostalgebraist, 2020), we can see very different semantics encoded in the representation of "cardinals" (sports, Catholicism, or birds) depending on the prompt that the word is found in.
Concept lens outputs for Llama-2-7b. We multiply the hidden state for inals at every layer by our concept lens matrix before projecting to token space. Applying this lens reveals the semantics of the token inals, which we can see depends on the context.
Our experiments show that concept induction heads are important for translation. Building on results from Dumas et al. (2025) showing that LLMs represent word meanings separate from language, we replicate their experiment in a more surgical way using these newly-found heads.
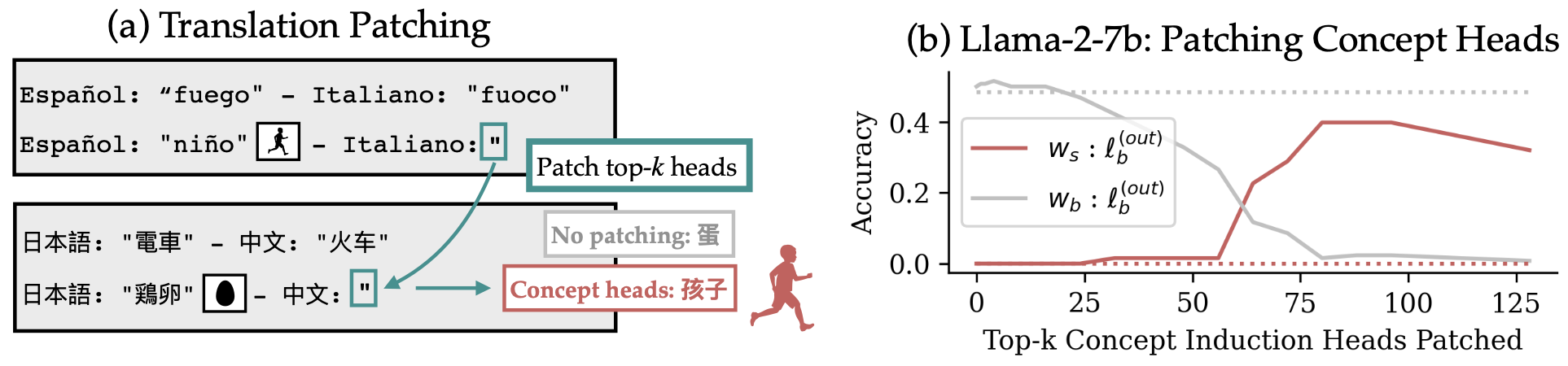
Patching the outputs of concept induction heads from the first prompt causes the model to output "child" in Chinese.
We use the same prompt setup as Dumas et al. (2025) to show that concept induction heads output representations of word meaning that can be expressed in multiple languages.
For example, if we take the outputs of concept induction heads when an LLM is translating "niño" ("child") from Spanish to Italian and substitute them into a context where the model is translating from Japanese to Chinese, we can get the model to output "child" in Chinese, "孩子". This suggests that these heads were carrying the meaning of the word "child," but not in any particular language. In other words, concept induction heads are important for translation because they specifically copy semantic information.
Kayo Yin, Jacob Steinhardt. Which Attention Heads Matter for In-Context Learning? 2025. Notes: The authors compare token induction heads to function vector heads, finding that FV heads are more important for ICL than token induction heads. Our work sheds light on why this might be: token induction heads, used for verbatim copying, are likely not as useful for ICL tasks as FV and concept induction heads are.
This work was accepted at COLM 2025. It can be cited as follows:
bibliography
Sheridan Feucht, Eric Todd, Byron Wallace, and David Bau. "The Dual-Route Model of Induction." Second Conference on Language Modeling, arXiv:2504.03022 (2025).
bibtex
@inproceedings{
feucht2025dualroute,
title={The Dual-Route Model of Induction},
author={Sheridan Feucht and Eric Todd and Byron Wallace and David Bau},
booktitle={Second Conference on Language Modeling},
year={2025},
url={https://arxiv.org/abs/2504.03022}
}





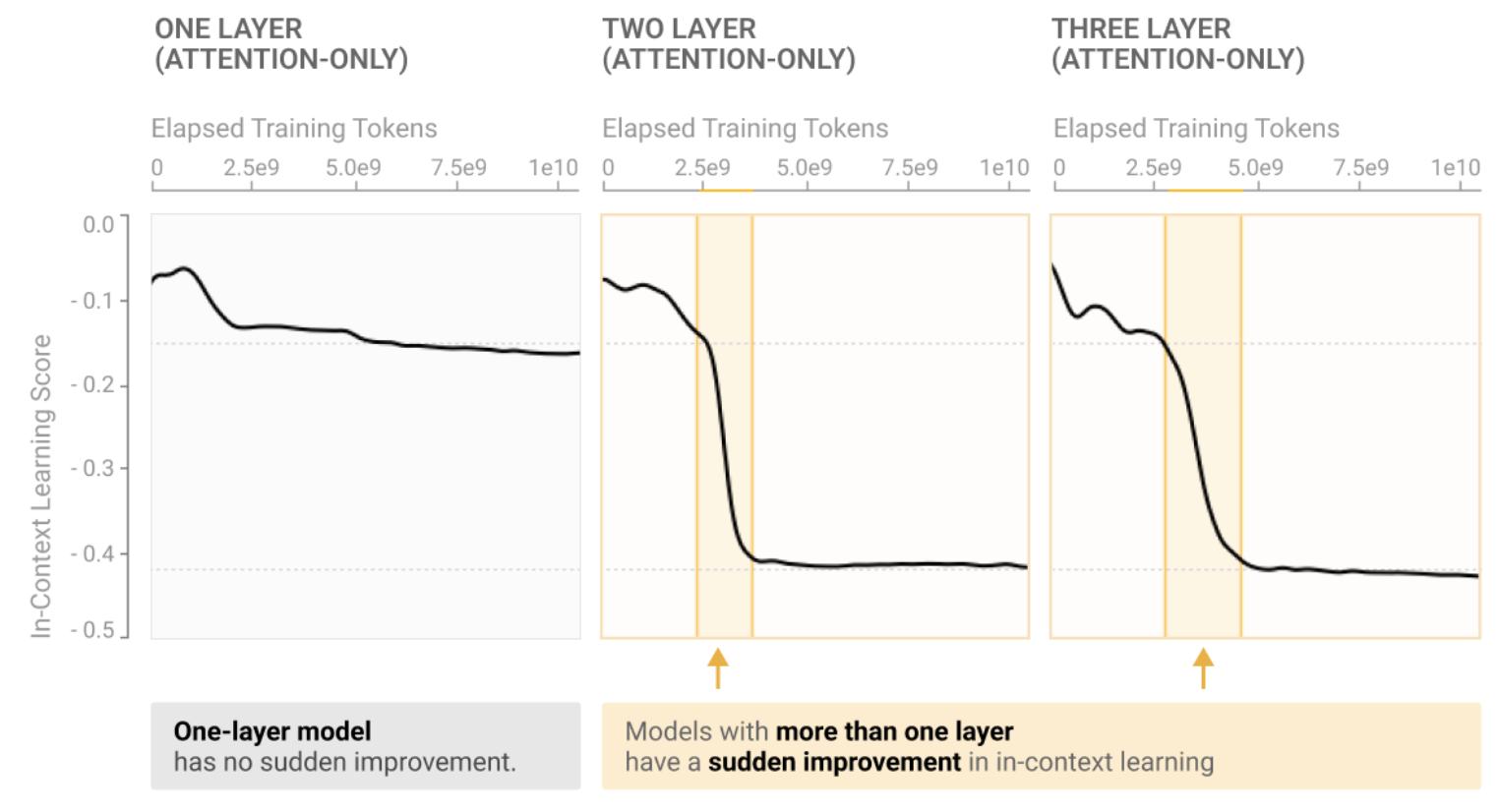 Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, ... Chris Olah. In-Context Learning and Induction Heads. 2022.
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, ... Chris Olah. In-Context Learning and Induction Heads. 2022.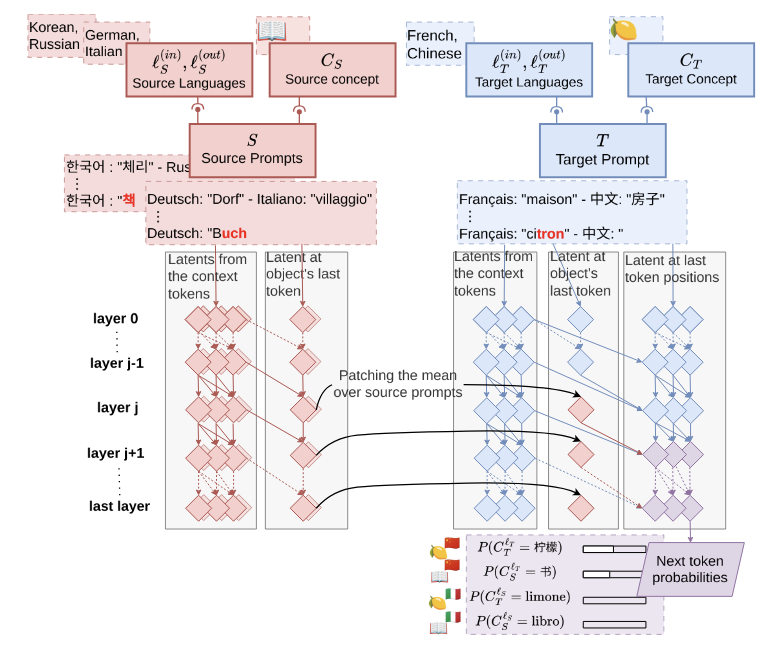 Clément Dumas, Chris Wendler, Veniamin Veselovsky, Giovanni Monea, Robert West. Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers. 2025.
Clément Dumas, Chris Wendler, Veniamin Veselovsky, Giovanni Monea, Robert West. Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers. 2025.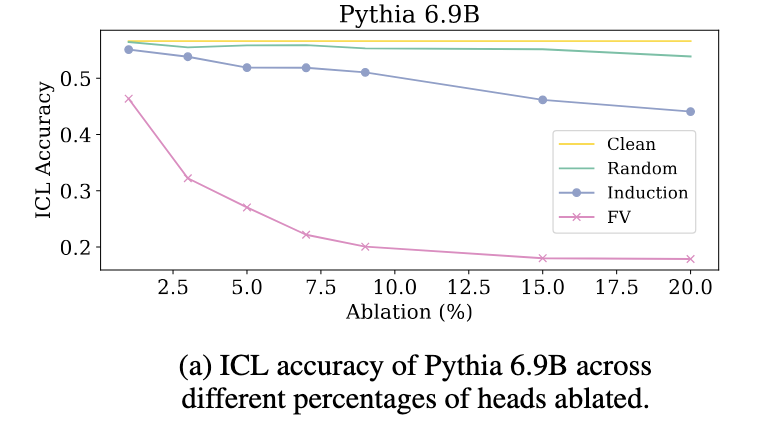 Kayo Yin, Jacob Steinhardt. Which Attention Heads Matter for In-Context Learning? 2025.
Kayo Yin, Jacob Steinhardt. Which Attention Heads Matter for In-Context Learning? 2025.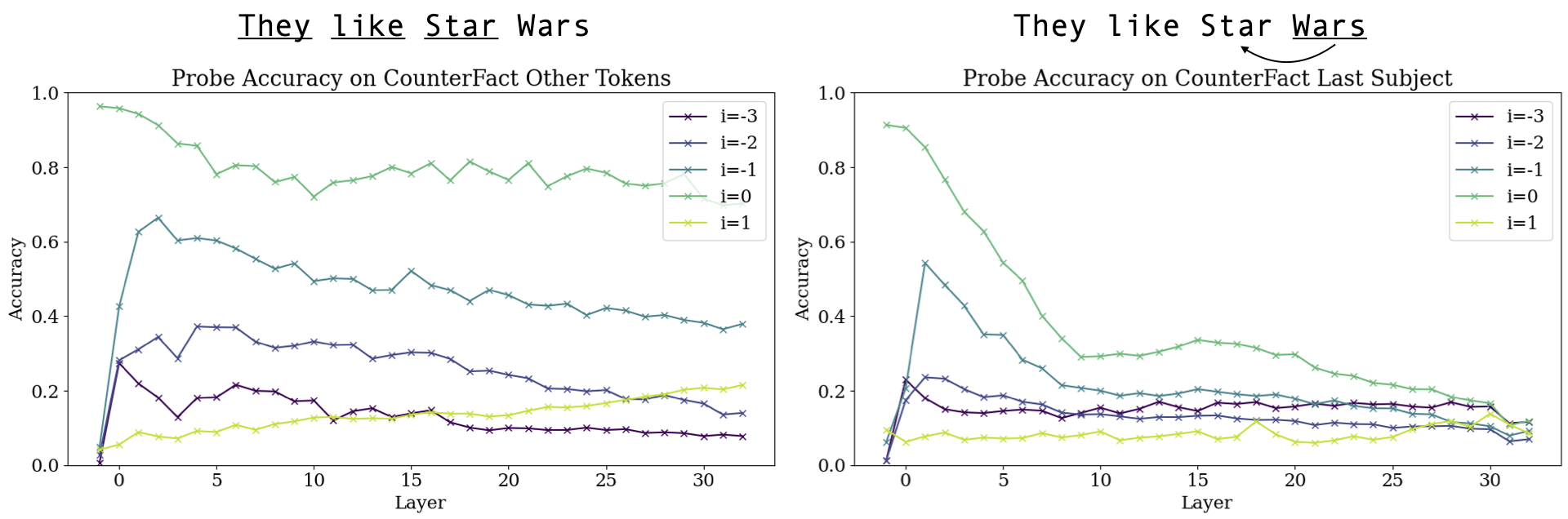 Sheridan Feucht, David Atkinson, Byron Wallace, David Bau. Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs. 2024.
Sheridan Feucht, David Atkinson, Byron Wallace, David Bau. Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs. 2024.